One of synthetic biology’s biggest challenges is mastering the art of protein folding and design. Although bioengineering techniques have advanced significantly in pursuit of this goal, synthetic biologists cannot perfectly design a protein’s sequence or shape purely through computer modeling or predictive algorithms. So what does the future of protein design look like, and how will it change what we can build with biology?
When Proteins Go Awry
For centuries, humans have been fascinated with decoding and recoding life. It has been one hundred and fifty years since Gregor Mendel’s famous experiments with pea plants set science on the path of genetics. Today, we understand not only how genetic traits can be inherited, but also how to change those traits through the read-write-edit cycle of DNA engineering. But the read-write-edit cycle is incomplete without the final output: proteins. Proteins are the end product of the DNA-to-RNA pathway. These critical molecules are everywhere from the food we eat to the antibodies that fight SARS-CoV-2. However, proteins sometimes fold incorrectly and malfunction, leading to serious genetic diseases. Certain mutations to the CFTR gene can lead to the misexpression of the protein that moves chloride ions out of cells, causing cystic fibrosis. The misfolding of another protein, amyloid beta, has been identified as a key factor behind Alzheimer’s disease. However, recent advances in protein research have helped develop therapeutics that can modify damaged proteins like the CFTR protein. This breakthrough creates a near-cure for a disease that has challenged researchers for decades.Misfolded proteins are representative of the challenges of designing proteins in general. Understanding and controlling how proteins behave and interact is central to advancing human and planetary health through biology. Whether the goal is driving immune responses with synthetic antibodies or increasing sustainability through plant-based meats, optimally designed proteins lie at the heart of this challenge.
Function Follows Form
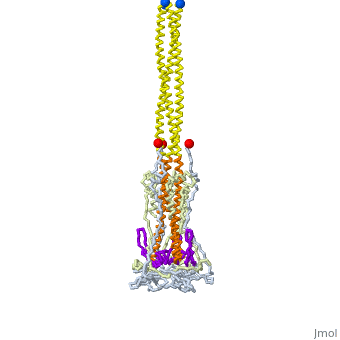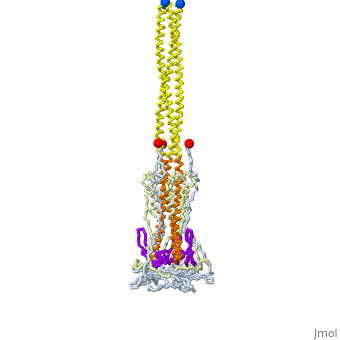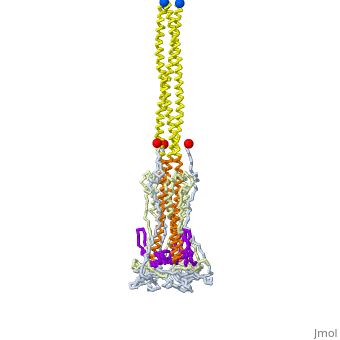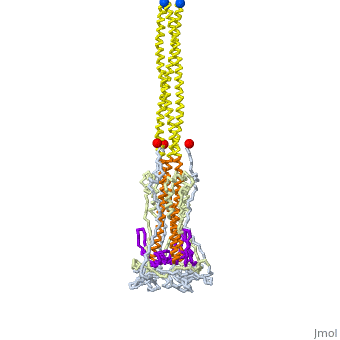
The SARS-CoV-2 spike protein unfolds to fuse the coronavirus membrane (red) with the host cell membrane (blue). Explore how this protein unfolds for yourself! A protein’s function is determined by its structure. The structure arises from how a protein folds, which in turn is encoded by the protein’s sequence. These relationships may sound straightforward but they are extremely difficult to model. There are too many possibilities to synthesize and laboriously test through when creating proteins in the lab to predict a protein’s structure--and therefore its function--accurately from its sequence.Traditionally, decision-making surrounding protein design is driven by biology and supplemented by computational methods. Methods such as peptide or gene synthesis and site-directed mutagenesis built datasets that validate sequences that have been computationally predicted as candidates to fold in a specific fashion. This approach is generally referred to as rational protein design. However, there are notable limitations to such techniques.Protein dynamics must be significantly simplified to be represented in synthetic systems. As a result, only a narrow range of protein features can be targeted for optimization rather than all aspects more holistically, particularly when considering this problem computationally. Additionally, a rigorous exploration of the “sample space” of possible sequences can be a computationally intensive task. Though this is less of a challenge today, the question remains: How do we best leverage computational tools to improve protein design, whether for drug discovery or sustainability?
Milestones for Computational Protein Design
Over the last several decades, advances in biological research and computing power have led to new methods of protein modeling and design. Computational protein design, designing proteins through computer modeling rather than lab experimentation, has become a central tool for creating more effective proteins in the pursuit of a healthier, more sustainable future. More recently, de novo computational protein design has come to the fore. The Baker Lab at the University of Washington has been successfully designing brand-new, never-before-seen proteins as early as 2003. This work has carried into their recent COVID-19 research developing small proteins as antivirals against the novel coronavirus. The Baker Lab’s work has been notably marked by a strong open-source ethos for computational protein design, with both its Rosetta modeling software for protein folding and interactions and the lab’s FoldIt computing network. This network enables citizen scientists to advance the lab’s work as well as the field at large. In a similar vein, blind prediction of protein structure has seen significant validation. Earlier this year, the DeepMind AlphaGo team reported unprecedented accuracy in their biennial challenge known as Critical Assessment of protein Structure Prediction (CASP), where teams predict 3D protein structures with no prior knowledge of it, save the protein sequence. AlphaGo represents its proteins as a spatial graph using structural and genetic data. This method, known as spacialomics, enables a better understanding of how proteins physically interact and how they evolved to their current form. Spacialomics is evaluated and optimized using a neural network—a class of computing algorithms inspired by the brain also referred to as a type of deep learning. The method will eventually allow for easier predictions of protein structure in the real world, superseding current techniques like cryoEM and crystallography through increased efficiency and decreased cost. While such methods already represent remarkable advances in computational protein design, for some, the discipline is on the cusp of the next generation of advances.
Deep Learning Meets Physics-Based Modeling

Vykintas Jauniskis, CSO and co-founder of Biomatter Designs“We believe that next-generation protein engineering lies in between the interplay of physics-based models and deep learning,” says Vykintas Jauniskis, CSO and co-founder of Lithuania-based company Biomatter Designs. The company is focused on developing a generative protein design platform through synthetic biology and AI. For Jauniskis, the intersection of these two technologies is a happy medium. Deep learning may not be as adept at predicting novel protein characteristics if those proteins are remarkably different from the data that those algorithms train on. Deep learning algorithms rely on learning and applying “rules'' to raw data, so if new protein types break those rules, deep learning isn't as effective. However, physics-based approaches that directly encode more detailed protein features and interactions are simply too slow. Jauniskis sees a middle ground in the form of generative protein engineering that leverages strengths from both approaches. For Jauniskis, this generative model is the “ideal approach that can unlock an engineer’s imagination.” Such an approach shifts the framework for an experiment towards more integrated modeling rather than just focusing on collecting vast amounts of data. This process could help standardize what can often be very messy datasets. Data can also be better prioritized in an intentional, pre-planned fashion, allowing for better comparison across studies. “When the field matures enough so specific ways to get the best kind of data and the projects are cheap enough, it is no longer a question of paying more for better data or not,” says Jauniskis. In other words, the cost of good data could cease to be a significant barrier to better research.

Surge Biswas, co-founder and CEO of Nabla BioBetter data is critical across the board, but better data doesn’t always mean more data. Surge Biswas, CEO of Nabla Bio (a company co-founded with Frances Anastassacos and George Church), sees leveraging smaller datasets as a frontier for next-generation protein design. “In contrast with prevailing methods that learn with a lot of high-throughput data, our platform learns from small amounts of sequence-account data, useful for a good composite representation and suggestions for new designs to be optimized,” he says. For Biswas, this approach is particularly important for high-value datasets that are relatively unique to synthetic biology.Like Jauniskis, Biswas envisions a future where computational approaches can become more effectively integrated with traditional molecular discovery and synthesis workflows. “Computation-first decision making is going to be the way to go because the rate of change of computational methods is orders of magnitude higher than wet lab techniques. Machine learning predictions are becoming almost, if not just as valuable as empirical lab data, but much easier to generate,” he remarks.
Designing Proteins for the Future
Human health is a major application area for next-generation protein design. Quickly designing antibodies has been at the forefront of public consciousness amidst this almost year-long pandemic. But Biswas also points to designer proteins in the food as a compelling space potential for computational protein design. The technology could be used to modify nutritional quality, learn how proteins impact taste, and explore previously unknown uses for proteins.Despite the excitement surrounding the next generation of protein engineering, both Jauniskis and Biswas express reservations about the promise of lightning-fast progress. Biswas particularly highlighted how the high cost of testing engineered proteins has limited what can be learned from drug clinical trials or industrial settings. These fields have relatively low data output but are missed opportunities to learn from computational mistakes and update datasets for future proteins. And yet, this is the age of big biology. If there were ever an era where such epistemological shifts are possible, a deep dive into the foundations of nature, it’s this one. Fundamentally rethinking how we collect data can allow the next generation of protein design to take off. Each iteration of protein design has the potential to improve global health, the future of food, and the sustainability of human life on this planet.








