Artificial Intelligence Reveals Protein-DNA Interactions
Protein structure prediction has improved significantly in recent years, but predicting their interactions with DNA will be key to realizing their applications
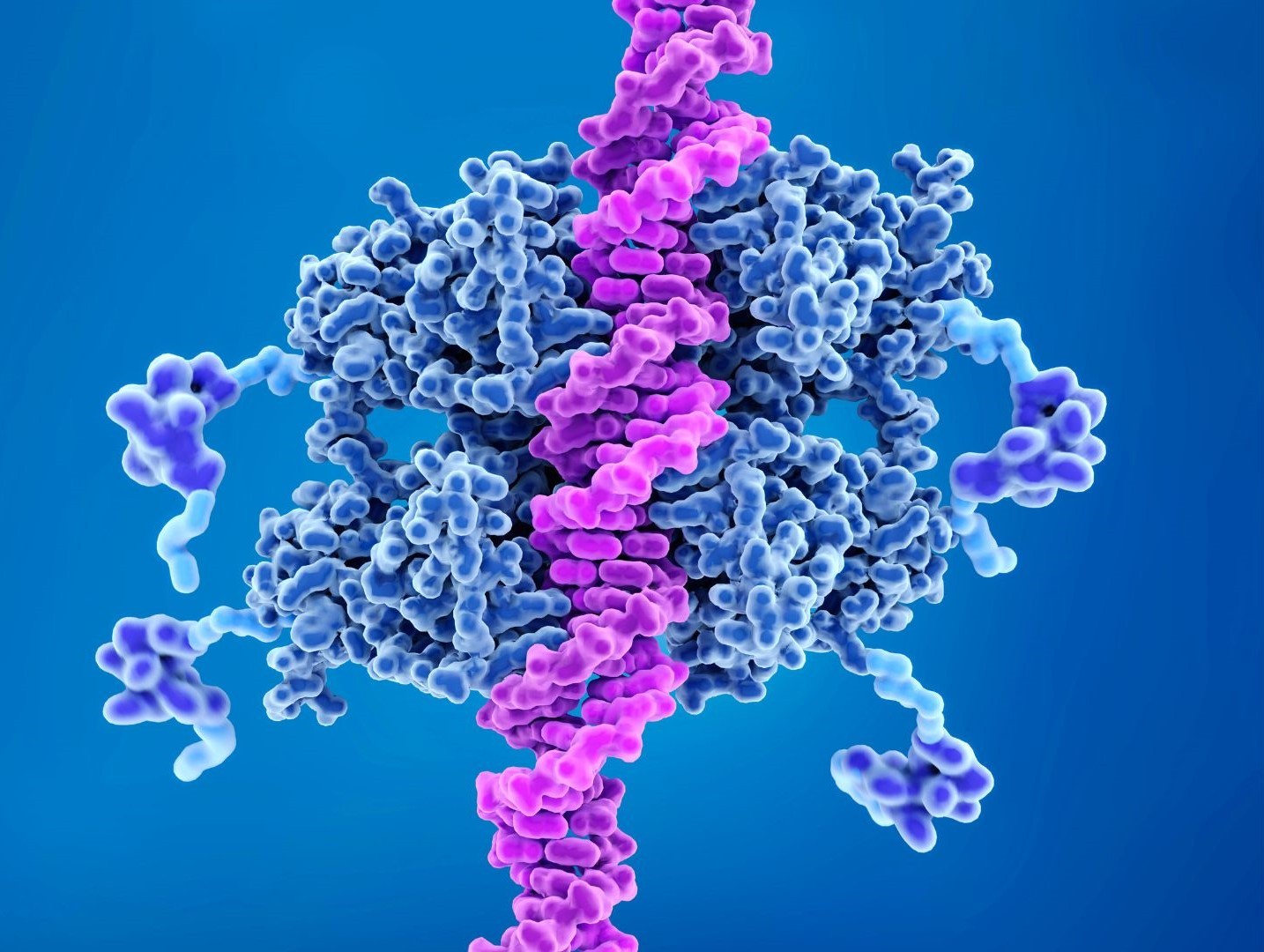
[Science Photo Library/Canva]
Protein-DNA interactions are vital in regulating cellular processes such as DNA replication, repair, and gene expression. Many diseases attributed to dysfunctional cellular processes or signaling pathways are essentially failures of these interactions. Mapping protein-DNA interactions, therefore, has substantial therapeutic implications.
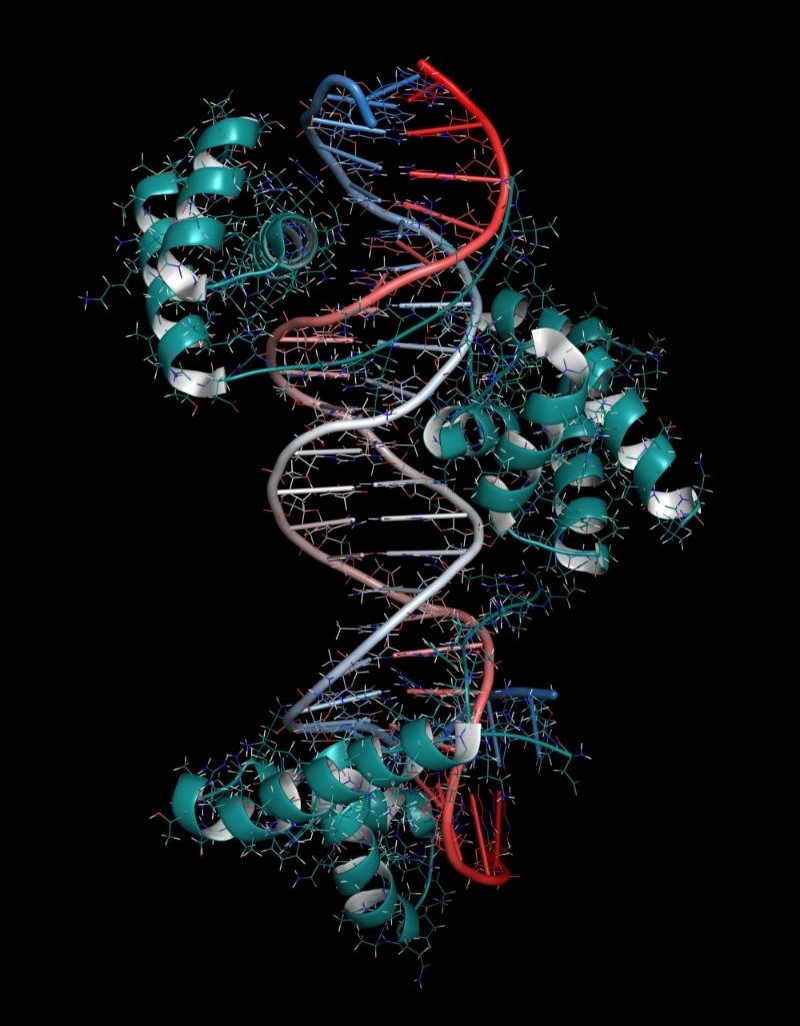
However, experimental methods to determine interactions between protein and DNA molecules, such as X-ray crystallography and cryo-EM, are costly and time-consuming. Of the over 245 million protein sequences published on UniProt, less than 1% are annotated with DNA-binding interactions. In recent years, protein structure prediction has improved significantly thanks to AI models like AlphaFold. Since protein structures determine their interactions with DNA, the same underlying technologies could bridge the gap in protein-DNA interactions.
Deep Learning Leads the Way
Early machine-learning approaches relied on knowledge of similar sequences or structures and amino acids that tend to co-evolve. Structures are more informative than sequences but are limited by the need for costly experiments. Of the over 221,000 experimentally determined structures on the Protein Data Bank, only a little over 13,000 are those of protein-nucleic acid complexes.
Deep learning overcomes this limitation. A subset of machine learning and the technology underlying tools like AlphaFold, it has shown promise in predicting protein structures and their interactions from sequence information. It utilizes layers of neural networks that act as a black box: the models can predict structures from sequences without revealing anything about the folding mechanisms.
Its third and latest iteration of AlphaFold announced in May this year extends its capabilities to predict protein structures as they interact with DNA and other entities like ligands and ions. Earlier, the team behind another protein structure prediction tool RoseTTAFold published a new iteration of the tool that predicts atomic scale structures of proteins in association with DNA and other ligands.
Both AlphaFold and RoseTTAFold leverage transformers, a type of deep learning architecture that learns context from sequential data. “It allows the model to focus on the most important areas for predicting protein bindings,” said Rory Kelleher, Global Head of Business Development at NVIDIA. “It can be fine-tuned on particular tasks to optimize the model performance for particular protein binding interactions.”
AlphaFold and RoseTTAFold use multiple sequence alignments as inputs for structure prediction. On the contrary, DNA and protein language models can infer knowledge about the structures from a single sequence. Think of these as large language models for the DNA/protein language.
For example, “DNABERT is trained on sequences from the human reference genome,” said Kelleher. Also built on the transformer architecture, it simplifies the genetic data into a form that highlights the most important and similar features across the genome. ”It encodes the relationships between different parts of the DNA sequence,” added Kellher. Researchers are using DNABERT to predict protein-DNA binding sites as well as improve existing models.
Just as large language models like ChatGPT learn statistical patterns in language, language models can figure out hidden correlations between different residues to identify DNA-binding patterns. ESMFold is a language model focused on protein structure prediction. Trained on sequences of millions of proteins, it can infer the full atomic-level protein structure from a primary sequence.
As the early success of these models shows, combining multiple machine-learning approaches is better at predicting protein structures and interactions. “The next generation solutions are not going to come from just individual models that solve individual problems, but from suites of solutions that are based on these virtual cycles of improvement between data sets and models,” said Lina Nilsson, SVP of Emerging Technologies at US-based biotech Recursion.
Enabling Data-Driven Proteomics
Artificial intelligence tools do not replace experiments to determine protein structures or interactions. Instead, they help scientists validate their ideas and experiment with more promising candidates. The feedback between experiments and AI means that the field is moving from identifying all DNA-binding sites on a protein or all proteins that bind a DNA motif to charting the complete landscape of protein-DNA interactions in an organism.
This shift illustrates how deep learning could tame the fuzziness of biology. “It is a really powerful tool to help us do the pattern recognition needed to understand biology and make it an engineering discipline.”
For drug discovery, this translates to generating way more hypotheses than previously possible. Rather than the function of a particular protein or gene, “we take a broad, unbiased view into biology,” said Nilsson. Recursion combines proteomics with data from transcriptomics, phenomics, cell morphology, and transcriptomics, among other modalities, and analyzes it using machine learning.
Studying all possible protein-DNA interactions will likely yield insights into how these interactions link to cellular mechanisms of different diseases and the role of the non-coding genome. The undruggable proteome has been a major bottleneck in drug development. “What that means is there are places in the proteome where there are binding sites that we just don’t know about,” said Nilsson. The opportunity, Nilsson added, is “using machine learning and large-scale relatable datasets to check what is tractable to go after.”
Predicting all possible interactions of a drug across the proteome could help researchers predict off-target interactions. Moreover, protein-DNA interactions are often impacted by the presence of other ligands around them. Predicting biomolecular interactions is key to improving the success of designing proteins.

Other than protein structure predictions, artificial intelligence enables data-driven proteomics by streamlining workflows. At Recursion, for instance, scientists use large language models to explore the maps of biology that they’re building, as well as interface with internal datasets and models and data sets.
Better Models for Engineering Biology
Predicting protein-DNA predictions has applications beyond drug development. For example, a greater understanding of these interactions will make it easier to engineer protein-based materials and synthetic gene circuits. To date, synthetic gene circuits have primarily been based on transcriptional control. Being able to design proteins from scratch and implement programmable logic in multi-domain proteins will allow custom gene circuits with translational control.
However, researchers still need to iron out some limitations of AI-based tools for protein-DNA prediction. Even when AI models predict the protein structure correctly, they can get the orientation or chirality of the biomolecules attached to them wrong. At other times, they can hallucinate structures that don’t exist. Moreover, these models don’t capture changes in protein structures over time or in different cellular contexts.
As more protein structures become available, both from high-throughput experiments and improved protein structure prediction software, there will be more data to train algorithms. Consequently, the predictive power of these models will improve. “The more unique and diverse data that you train these models with, the better the capabilities will be for genomic interpretation or prediction tasks,” said Kelleher.









